Publications
Data Lake for managing unstructured data
Backing up a large volume of unstructured data
For more than 30 years, our automated quality control systems and our test benches have generated a very large amount of data. Some of our systems have acquired data from 100% of products exiting our customers' production lines for over 10 years. We now want to offer new functions highlighting data for example to better understand production processes. To do this, it is necessary to centralize all the data and to be able to do intelligent research. The Data Lake is the ideal tool, so we have initiated a process to add their expertise to QMT's know-how portfolio.
QMTMesure softwareData management and their valuation
A data lake is a means of storing data of different kinds in their original formats. At the macro scale, there are 3 types of data present in a data lake:
- Structured data such as data in a database, or an Excel file
- Semi-structured data such as * .xls, * .csv, * .json files or logs
- Unstructured data such as image, sound or text files
The distinction between structured and unstructured data is made by the characteristic of a data with which a user works. On structured data, it works on the value (s) of the data while for unstructured data it works with information on this data. This information is called metadata or "Tags".
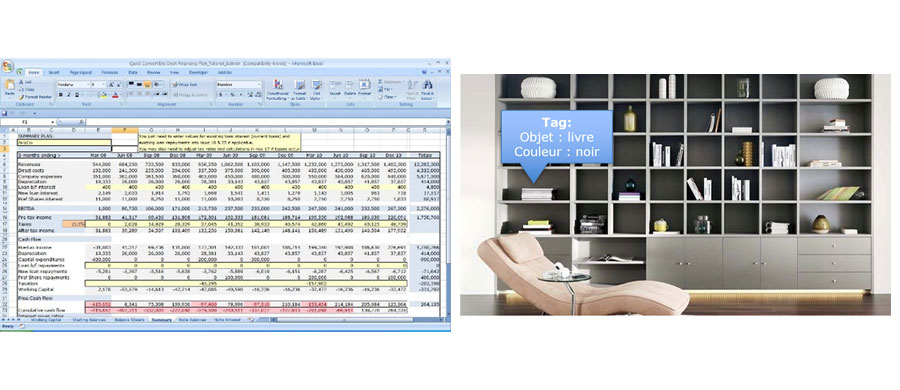
Left: example of structured data (an Excel file); Right: a library which schematizes a Data lake with unstructured data but recognizable with their labels ("Tag").
Amazon, Microsoft and Google are the leaders in data lake tools. We compared Amazon's AWS and Microsoft's Azure.
Amazon AWS
- Basic cloud solution with internal localization option (planned for 2020)
- The different services are offered "à la carte" in order to be able to create your ideal solution
- The costs are low
Microsoft Azure
- Large customer base with the Microsoft name
- Cumbersome implementation and poor visibility of changes and their impacts
- High costs and not very transparent
We chose the AWS solution to standardize our solutions
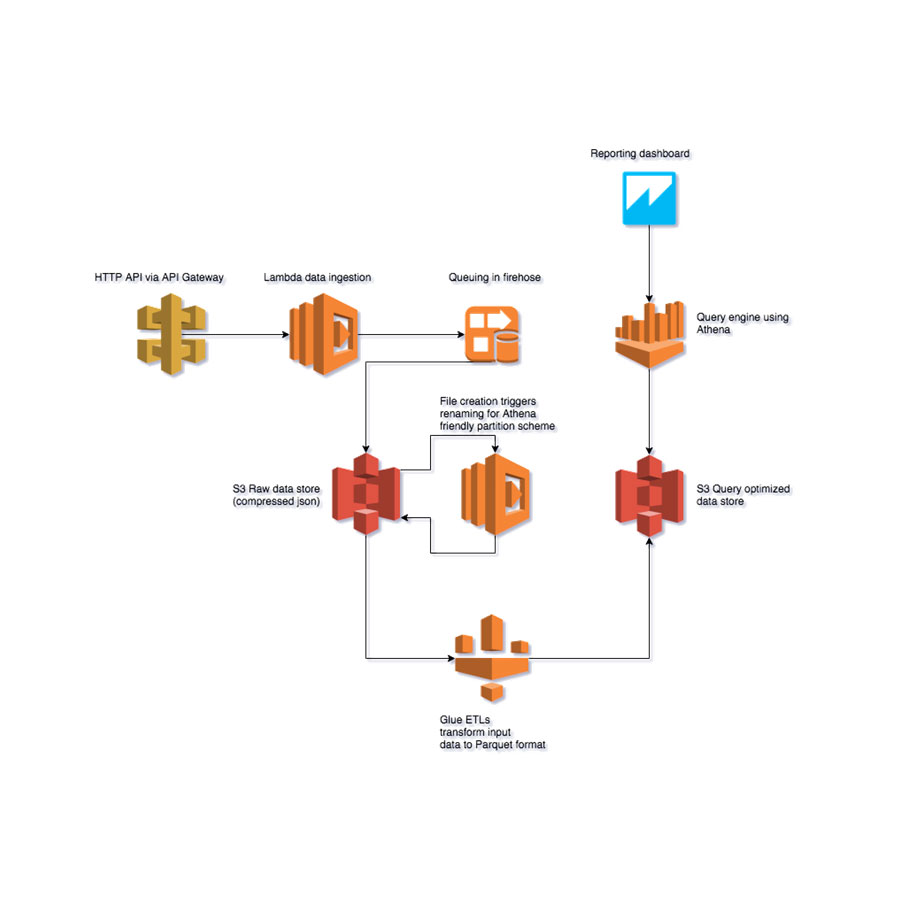
We have set up a Data Lake for our use with the following:
- An S3 Bucket data server in Ireland
- AWS Glue Structured Data Catalog (ETL & Data Catalog)
- Amazon Athena Structured Data Queries Engine (Interactive queries)
- Amazon ES (Elastic Search) elastic search engine for unstructured or semi-structured data with its Kibana graphical interface
- QuickSight Data Viewer
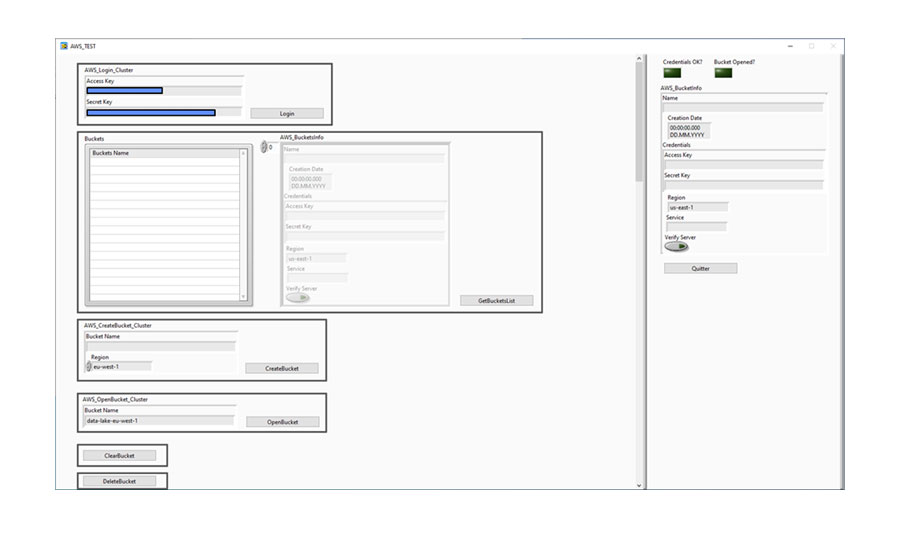
We have developed a software tool that easily integrates with our systems to add labels to data, send them to the data lake and find them with Elastic search.
The next steps are to standardize the labels (or tags), to adapt the QMT tool to the management of standard tag catalogs and to simplify the search for Tags by our tool.
We will thus be ready to apply artificial intelligence tools to the data in order to study the correlations between the data.




