Technologies
Data Lake zur Verwaltung unstrukturierter Daten
Sichern einer großen Menge unstrukturierter Daten
Seit mehr als 30 Jahren generieren unsere automatisierten Qualitätskontrollsysteme und unsere Prüfstände eine sehr große Datenmenge. Einige unserer Systeme erfassen seit über 10 Jahren Daten von 100% der Produkte, die aus den Produktionslinien unserer Kunden stammen. Wir möchten jetzt neue Funktionen anbieten, die Daten hervorheben, um beispielsweise Produktionsprozesse besser zu verstehen. Dazu ist es notwendig, alle Daten zu zentralisieren und intelligent recherchieren zu können. Der Data Lake ist das ideale Tool. Daher haben wir einen Prozess eingeleitet, um das Know-how des QMT-Know-how-Portfolios zu erweitern.
QMTMesure-SoftwareDatenmanagement und deren Bewertung
Ein Datensee ist ein Mittel zum Speichern von Daten verschiedener Art in ihren ursprünglichen Formaten. Auf der Makroskala sind in einem Datensee drei Arten von Daten vorhanden:
- Strukturierte Daten wie Daten in einer Datenbank oder eine Excel-Datei
- Halbstrukturierte Daten wie * .xls, * .csv, * .json-Dateien oder Protokolle
- Unstrukturierte Daten wie Bild-, Ton- oder Textdateien
Die Unterscheidung zwischen strukturierten und unstrukturierten Daten erfolgt durch die Eigenschaft von Daten, mit denen ein Benutzer arbeitet. Bei strukturierten Daten werden die Werte der Daten verarbeitet, bei unstrukturierten Daten Informationen zu diesen Daten. Diese Informationen werden als Metadaten oder "Tags" bezeichnet.
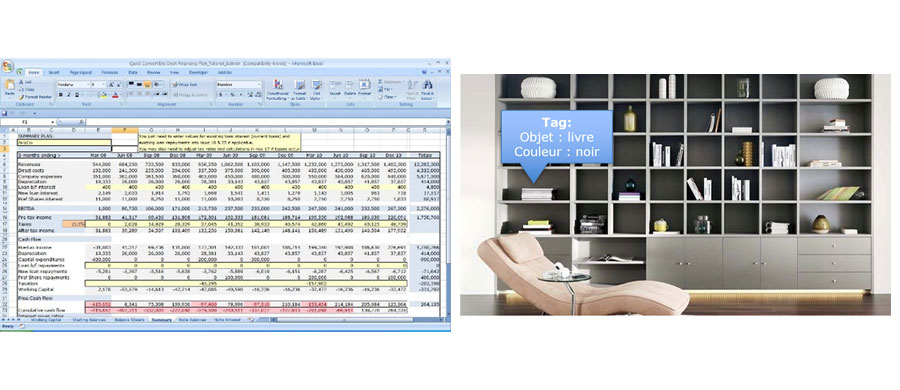
Links: Beispiel für strukturierte Daten (eine Excel-Datei); Rechts: Eine Bibliothek, die einen Datensee mit unstrukturierten Daten schematisiert, aber anhand ihrer Beschriftungen erkennbar ist ("Tag").
Amazon, Microsoft und Google sind führend bei Data Lake-Tools. Wir haben Amazon AWS und Microsoft Azure verglichen.
Amazon AWS
- Grundlegende Cloud-Lösung mit interner Lokalisierungsoption (geplant für 2020)
- Die verschiedenen Dienstleistungen werden "à la carte" angeboten, um Ihre ideale Lösung zu erstellen.
- Die Kosten sind gering
Microsoft Azure
- Großer Kundenstamm mit dem Namen Microsoft
- Umständliche Implementierung und schlechte Sichtbarkeit von Änderungen und deren Auswirkungen
- Hohe Kosten und nicht sehr transparent
Wir haben uns für die AWS-Lösung entschieden, um unsere Lösungen zu standardisieren
Wir haben einen Data Lake für unsere Verwendung eingerichtet, der Folgendes umfasst:
- Ein S3 Bucket-Datenserver in Irland
- Strukturierter AWS Glue-Datenkatalog (ETL & Datenkatalog)
- Strukturierte Datenabfrage-Engine von Amazon Athena (interaktive Abfragen)
- Elastische Suchmaschine von Amazon ES (Elastic Search) für unstrukturierte oder halbstrukturierte Daten mit ihrer grafischen Oberfläche von Kibana
- QuickSight Data Viewer
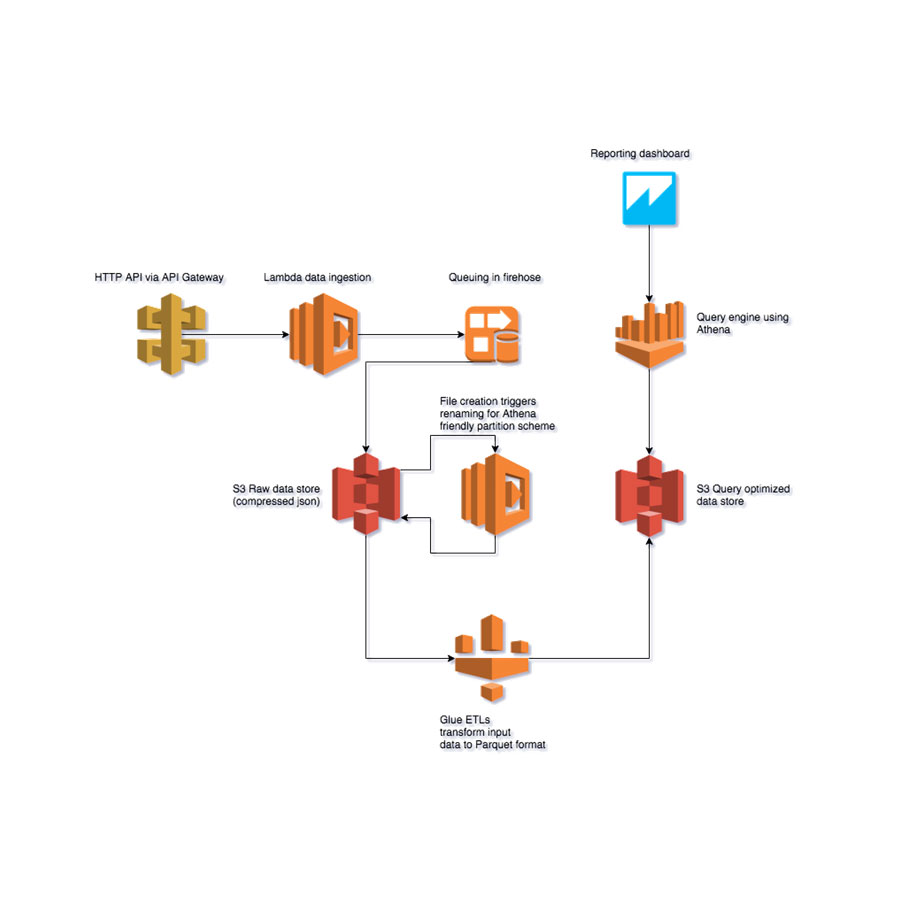
Wir haben ein Softwaretool entwickelt, das sich problemlos in unsere Systeme integrieren lässt, um Daten Etiketten hinzuzufügen, sie an den Datensee zu senden und sie mit der elastischen Suche zu finden.
Die nächsten Schritte bestehen darin, die Beschriftungen (oder Tags) zu standardisieren, das QMT-Tool an die Verwaltung von Standard-Tag-Katalogen anzupassen und die Suche nach Tags durch unser Tool zu vereinfachen.
Wir werden daher bereit sein, Werkzeuge für künstliche Intelligenz auf die Daten anzuwenden, um die Korrelationen zwischen den Daten zu untersuchen.