Technologies
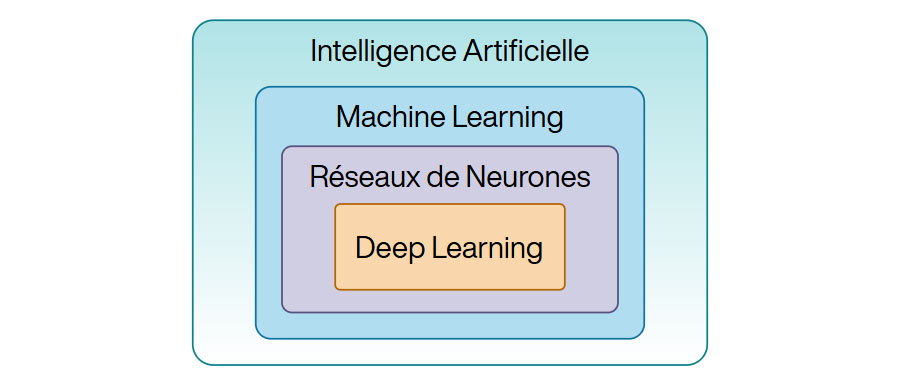
Intelligence Artificielle

Des machines plus intelligentes et pensantes pour qu’elles agissent comme des humains
Depuis plus de 30 ans, nos systèmes de contrôle qualité automatisés et nos bancs de test prennent des décisions pour garantir un contrôle performant. Aujourd'hui, les technologies évoluent et les attentes sont plus élevées : nous ne voulons plus programmer les machines, nous voulons qu'elles apprennent d'elles mêmes. C'est l'Intelligence Artificielle.
Tout le monde parle de l'Intelligence Artificielle, mais en fait c'est quoi ?
Est-ce vraiment possible de réaliser du contrôle qualité à 100% sans risque d'erreurs avec cette technologie?
Logiciels QMTMesureIntroduction
On peut définir l’Intelligence Artificielle comme un système automatique constitué de topologies algorithmiques apprenantes permettant des prises de décisions par prédiction.
L’IA est dominée par l’Apprentissage Automatique (Machine Learning). Le Machine Learning est une sous-catégorie de l'IA qui permet à un ordinateur de découvrir des motifs dans des données à partir d’algorithmes ajustés par des passes d'apprentissages. On lui associe par exemple, les régressions linéaires, les arbres de décisions, les calculs de proches voisins KNN, les K-means pour le traitement des clusters de données…
Le Machine Learning possède une sous-catégorie nommée Apprentissage Profond (Deep Learning). Le Deep Learning exploite des réseaux de neurones et filtres convolutifs disposés en couches hiérarchiques entrainés directement à partir de grandes quantités de données stockées numériquement sous forme de séries de données, d’images, de texte, d’échantillons de signaux provenant de capteurs physiques.
Ces modèles s’appuient sur des librairies d’algorithmes éprouvés qui, chainés et paramétrés structurent automatiquement des représentations abstraites et pertinentes selon la quantité de données sur lesquelles elles sont entraînées.
L’IA contemporaine est excellente pour traiter des tâches spécifiques. Les algorithmes d’IA ont la capacité de raisonner sur un domaine choisi lors de leur entrainement. Les travaux de recherche actuels se concentrent sur l'Intelligence Artificielle Générale pour obtenir des capacités cognitives humaines ou super-humaines dans tous les domaines.
Le Deep Learning est une sous-catégorie du Machine Learning qui utilise spécifiquement des réseaux neuronaux complexes pour analyser des données et effectuer des prédictions ou classifications avancées.
Le schéma suivant illustre le principe de classification par deep learning. Un modèle de détection par vision subit un processus d’apprentissage. Des images de divers objets distincts vont activer des chemins de son réseau de neurones et en désactiver d’autres. Après obtention du modèle final, l’image d’une montre nouvelle est facilement détectée et sa classe est prédite avec un score de confiance.
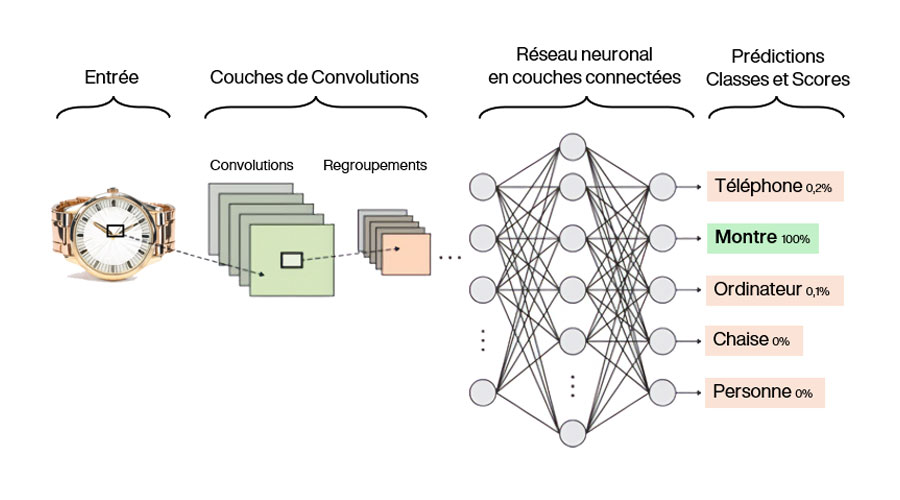
On note que si deux images de deux classes utilisées pour l’entrainement possèdent des caractéristiques visuelles proches, les scores de confiance en sortie du modèle peuvent être faibles. Le modèle n’arriverait pas à les distinguer, provoquant possiblement un risque de générer des fausses prédictions.
L’humain doit donc toujours avoir un avis critique s’agissant des données d’entrées et de l’entrainement réalisé pour corriger ou accepter les marges d’erreurs.
La raison principale est motivée par les cas d’usages dont la complexité des données en entrée ne pourraient permettre à des détecteurs, utilisant des méthodes de traitement du signal conventionnelles, de bien fonctionner.
Les données d’entrée doivent être disponibles, exhaustives et sans biais. Les modèles sont des boites noires qu’il est difficile pour un humain de sonder. L’interprétation des résultats des modèles est cruciale pour leur utilisation.
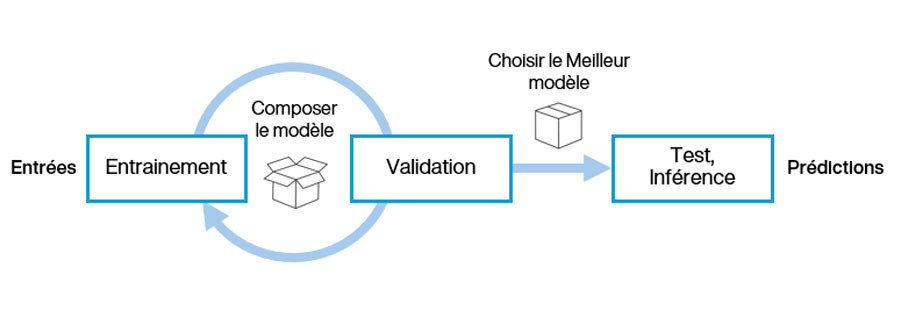
Dans tout modèle d’apprentissage, il est nécessaire de distinguer l’entrainement de l’inférence. L’entrainement est l'étape consitant à choisir une structure de modèle, démarrer un apprentissage paramétré et à optimiser le modèle par des itérations de validations successives. Le but des itérations est de minimiser l'erreur de perception finale du modèle. L’inférence est l’utilisation d’un modèle sur des données de test ou sur des données en situation nouvelle. Le schéma suivant illustre les étapes majeures nécessaires de suivre en machine learning :
Le traitement du langage naturel permet aux machines de comprendre et d'interagir avec le langage humain. Les LLMs comme ceux des assistants ChatGPT, Copilot, Claude, Llama ou Gemini sont aussi construits sur des principes d'apprentissage profond, en utilisant des couches telles que les couches de prédiction, d'intégration et d'attention. Ils utilisent des mécanismes comme l'auto-attention pour comprendre l'importance des différents mots dans une séquence. Ces modèles sont entraînés sur de vastes ensembles de données à l'aide de l'apprentissage auto-supervisé, ce qui signifie qu'ils apprennent à prédire le mot suivant dans une phrase en fonction du contexte fourni par les mots précédents
Les données d’entrées: natures et organisation
Les données sont de natures variées: elles peuvent par exemple être produites par des capteurs analogiques générant des images, des signaux acoustiques, vibratoires, électromagnétiques, de température ou autres.
Le Datalake est un espace de stockage constitué des ensembles de données brutes récupérées et stockées dans leur format natif. Ces données n’ont pas encore fait l’objet d’analyses manuelles pour trier et mettre de côté les données vraiment exploitables ainsi que pour structurer leur organisation par répertoires ou nommage de fichiers.
Le Datawarehouse est un espace de stockage constitué de lots de données (datadets) organisés et triés en répertoires, et propres à être utilisés pour la création de modèles.
Le Dataset est l’ensemble des données d’entrées du processus d’entrainement permettant de générer des modèles.
Les images d’un même dataset sont dans un format commun. Par exemple : au format PNG ou JPG et de résolution identique pour les images, au format WAV pour les sons, en TXT ou CSV pour les données.
On divise le dataset en deux lot de données pour l’entrainement: typiquement 80% pour l’entrainement et 20% pour la validation.
C’est un compromis à trouver : Si le pourcentage de validation n’est pas assez grand, le modèle aura tendance à ne pas bien détecter des images nouvelles, le modèle est dit en “overfitting”.
A contrario, si il est trop petit le modèle risque de ne pas être entrainé sur un volume d’image suffisant si le dataset est petit, le modèle est dit en “underfitting”
Les données d’entrées doivent être annotées avec des labels correspondant à des classes. Ces annotations correspondent aux caractéristiques que l’on souhaite identifier par nommage dans les données.
L’annotation peut être globale à une image ou à des série de données, ou bien être locale, sous la forme de plages d'échantillons contiguës.
Elle peut être effectuée manuellement, automatiquement ou par assistance d’un détecteur déjà entrainé.
Les modèles non-supervisés ne requiert pas d’annotation.
Le réseau neuronal convolutif (CNN) au coeur du deep learning
Les CNN conçus pour une tâche de classification sont une suite de fonctions contenant principalement un extracteur de caractéristiques en amont et un classificateur en aval.
L'extracteur de caractéristiques (“feature extractor”) comprend des blocs convolutifs composés d'une ou plusieurs couches convolutives (“convolutive layers”) suivies d'une couche de regroupement (“max pooling layer”).
Les blocs convolutifs extraient des caractéristiques significatives de l'image d'entrée, en passant par les couches connectées (“fully connected layers”) pour la tâche de classification.
Les couches convolutives extraient les caractéristiques de la couche précédente et stockent les résultats dans des cartes d'activation (“activation maps”)
Les couches de regroupement sont souvent utilisées à la fin d'un bloc convolutif pour réduire le nombre total de paramètres pouvant être entraînés dans le réseau et, par conséquent, le temps d'entraînement nécessaire. De plus, cela permet également d'atténuer le surapprentissage.
Lorsque le nombre de classes est supérieur à deux, une couche SoftMax est utilisée pour normaliser la sortie brute du classificateur à la plage [0,1]. Ces valeurs normalisées peuvent être interprétées comme la probabilité que l'image d'entrée corresponde à l'étiquette de classe de chaque neurone de sortie.
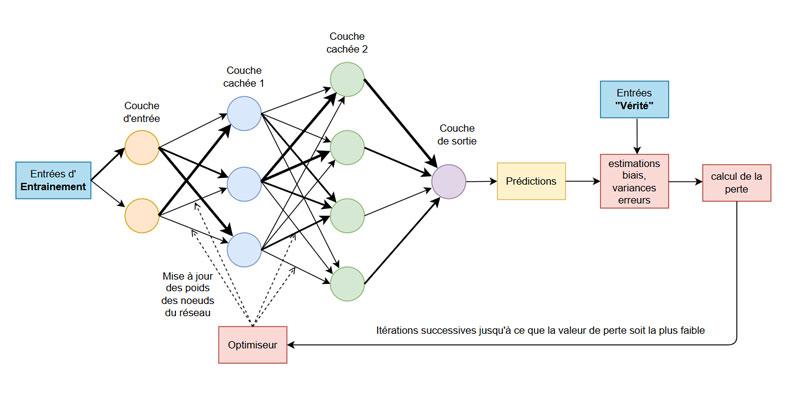
La partie classificateur du réseau transforme les entités extraites en probabilités de classe à l'aide d'une ou plusieurs couches densément connectées. Pour expliquer son fonctionnement, le schéma suivant illustre la structure commune d’un CNN par couches denses de noeuds représentant des neurones. Les neurones sont tous inter-connectés. A chaque connexion, on associe un poids dont l’optimiseur sera chargé de modifier lors de l’apprentissage. L’objectif sera de minimiser la perte entre les données d’entrainement traitées par le modèle et les données représentant la vérité c’est à dire les données non altérées par le modèle.
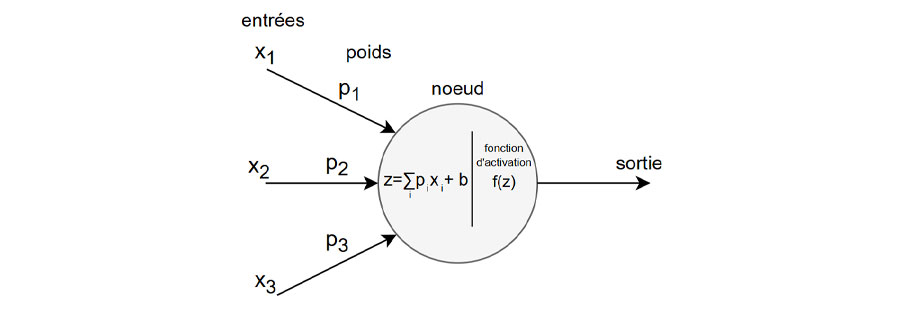
L’unité de calcul du réseau neuronal est un noeud réalisant la somme des entrées pondérées individuellement par des coefficients à laquelle on ajoute une valeur de biais. Une fonction d’activation y est aussi appliquée (les plus connues étant ReLU, Tanh et Sigmoïd).
Les différents modes et la méthodologie
- La détection d’anomalies
La détection d’anomalies consiste à identifier des données inhabituelles en entrée d’un automate de vérification. La détection peut s’effectuer par classification ou par segmentation. - La classification d’images
La classification a pour principe de créer une liste de classes distinctes et de s’en servir pour annoter les images utilisées pour l’entrainement du modèle.
En détection d’anomalies, on pourra utiliser les classes OK ou NOK, ou bien créer une classe par défaut recherché.
Lors de l’inférence, le nom de la classe sera la sortie principale du modèle, elle est généralement accompagnée du score de confiance. - La détection d’objets par segmentation
La détection d’objets par segmentation permet de vérifier la présence, les occurrences et les natures des objets présents dans une image.
C’est donc une opération plus précise que la classification d’images puisque la segmentation agit au niveau des pixels.
En détection d’anomalies, il faut annoter avec précision les pixels identifiant les défauts et uniquement ceux là. - La prédiction
L’apprentissage d’un modèle de prédiction sur des données connues permet d’anticiper les états futurs d’un flux de données réel. Ces modèles sont adaptés aux séries de données temporelles.
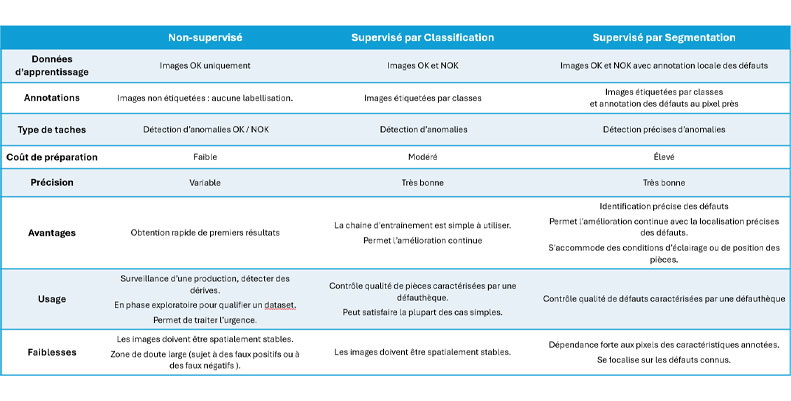
Le tableau ci-dessous détaille les modes d’apprentissage en Vision
Par définition, un modèle non supervisé est obtenu grâce à un processus qui n’a reçu aucun apprentissage lui indiquant le résultat en sortie.
Dans cette approche, il n'est pas nécessaire d’annoter les données et seulement des données conformes sont nécessaires en entrée.
Par exemple, pour obtenir un modèle de classification qui discrimine un résultat conforme (OK) d'un résultat non-conforme (NOK), l’entrainement du modèle sera réalisé uniquement sur des données normalement conformes (OK). Il prédira alors les données non-conformes par opposition aux caractéristiques conformes apprises.
En vision industrielle, ces modèles sont appropriés pour des applications de surveillance et de dérive de production mais manqueront de précision de détection si l’image n’est pas spatialement stable.
Un apprentissage supervisé requiert l’annotation des données d’entrée. La création d’’annotation permet d'améliorer la précision de la détection et de la localisation des anomalies. Le principe consite à créer un masque binaire constitué de noir pour des pixels d’une zone sans défaut et de blanc pour des pixels d’une zone avec défaut.
Les masques sont créés manuellement pour chaque image anormale du dataset. Ils représentent la localisation des défauts au pixel près. Aucun masque n’est donc requis pour les images normales.
Sur cette vue, on annote les défauts par contour ou par segmentation automatique (en cliquant sur le défaut ou en entourant par un rectangle la zone concernée, l’outil trouve lui même les pixels concernés.)

Le masque ainsi obtenu est aussi appelé Ground Truth, il va être exploité lors du calcul de perte pour optimiser le modèle.
L’augmentation des données est une technique utilisée pour tirer partie des données disponibles en faisant varier légèrement leur contenu par ajout de bruits, filtrages, transformations géométriques (rotation, miroir, étirement).
L’optimisation du modèle lors de l’entrainement peut être laborieuse si les images constituant le dataset sont non homogènes, si elles contiennent du bruit et des différences de contraste.
De plus, il est primordial que les images capturées lors de l’inférence restent similaires avec celles qui ont été utilisées pour créer le modèle. Les perturbations doivent être minimisées ou doivent être de mêmes types et de même quantité.
Il est impératif que le prétraitement des images avant l'entrainement d’un modèle doit être identique à celui utilisé pour l’inférence. Ainsi, la normalisation le filtrage, le contraste, la rotation, le recadrage, l'échelle, la résolution, les zones d’intérêts doivent être parfaitement répliquées.
La conséquence sera que le modèle de Machine Learning surapprenne des détails spécifiques aux images d’entrainements et échoue à bien détecter sur les images capturées à l’inférence.
L'entrainement
Une epoch correspond à une itération complète où toutes les données d’entrainement sont utilisées une fois pour mettre à jour les paramètres du modèle. A chaque epoch le modèle calcule les erreurs et ajuste les poids et biais pour minimsier ces erreurs jusqu'à ce que le modèle atteigne un niveau de performance satisfaisant.
- Training Set (ensemble utilisé pour entraîner le modèle)
Il s’agit de la plus grande partie de l’ensemble de données pour permettre au modèle d'apprendre efficacement les caractéristiques cachées dans les données.
À chaque « epoch », les mêmes données d'entraînement sont transmises à l'architecture du réseau neuronal.
Le jeu d'apprentissage doit avoir un ensemble diversifié d'entrées afin que le modèle soit entraîné dans tous les scénarios et puisse prédire tout échantillon de données invisible qui pourrait apparaître à l'avenir.
Pour une classification non supervisée, l’entrainement se réalise sur des données purement OK - Validation Set (ensemble utilisé pour vérifier la perte de précision du modèle) : L'évaluation du modèle est effectuée sur l'ensemble de validation après chaque « epoch » de la Train loop
L'idée principale de l'ensemble de données de validation est d'éviter que le modèle ne s'ajuste, c'est-à-dire que le modèle devienne vraiment bon pour classer les échantillons dans l'ensemble de training, mais ne peut pas généraliser et faire des classifications précises sur les données qu'il n'a pas vues auparavant.
Pour une classification non supervisée, la validation s’effectue sur des données OK et NOK - Testing Set (ensemble utilisé pour évaluer les performances du modèle sur des données inconnues du modèle après l’entrainement)
Il ne doit pas être utilisé pendant le processus de formation pour garantir une évaluation impartiale.
L'ensemble de test est un ensemble distinct de données utilisé pour tester le modèle une fois l'entraînement terminé.
Il permet de réaliser une mesure de performance finale impartiale du modèle en termes d'exactitude, de précision. En classification, on obtient la liste des classes OK/NOK détectées et le taux de confiance sur le dataset de test.
Ainsi on quantifie la proportion de la prédiction à dévier de la vérité.
Les proportions de données d'entraînement sont généralement de l’ordre de 80% et de 20% pour les données de validation.
Par simplicité pour l’utilisateur, des moteurs d’entrainement peuvent eux-même séparer aléatoirement les images d’entrainement et de validation. pour la réplicabilité de l’entrainement sur un même lot d’image, il est préférable que cette séparation reste toujours la même.
Un modèle peut être soumis à un risque d’ ”underfitting” quand il est insuffisamment entrainé, il n’arrive alors pas à détecter convenablement.
A l’opposé, il peut être soumis à un risque d’ ”overfitting” quand il est entrainé trop précisément sur les données d’entrée et ne peut plus être performant sur des données nouvelles qui diffèrent.
L’Early Stopping consiste à arrêter l’entrainement avant qu’il n’entre en overfit. Lors de l’entrainement la fonction “Loss” qui compare les résultats prédits avec les résultats attendus permet de détecter le point optimum avant over-fitting.
L’algorithme d’entrainement du modèle exploite un concept nommé “compromis biais-variance”. Il calcule le biais statistique, c’est à dire l'erreur systématique qui fait que les estimations s'écartent de la valeur réelle. Par exemple, le biais d'un estimateur est la différence entre la valeur moyenne de cet estimateur et la vraie valeur du paramètre estimé. Il calcule aussi la variance qui indique de combien les estimations dévient de la prédiction moyenne.
Les hyperparamètres les plus courants sont learning rate, batch size, number of epochs, data augmentation.
D’autres ne sont pas toujours accessibles à l’utilisateur du modèle, et peuvent être figés: Activation function (ReLU, Sigmoid, Tanh), Drop out Rate, Weights Optimizer (Adam…), Weight Initialization, Kernel Size,…